ML Accelerator DataFlow: Output Stationary in three approaches
The Notebook of the post is provided in this GitHub Link
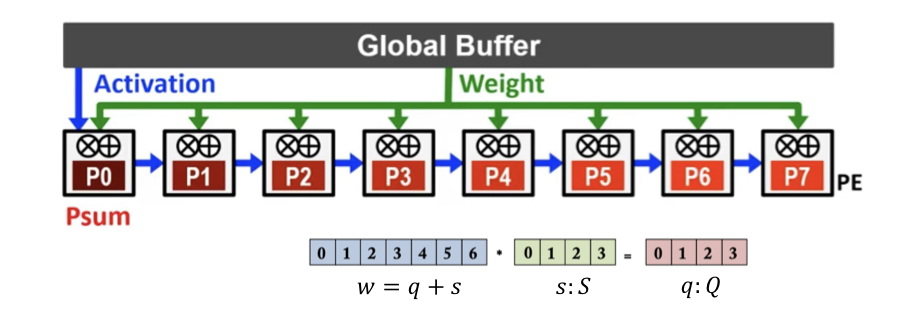
- image from EE-599 slides
In course USC EE-599:”Systems for Machine Learning”, we learned three types of data-flow techniques often used in hardware accelerators: weight stationary, input stationary, and output stationary. In output stationary architecture, the output data remains stationary in the Processing Elements(PEs) while the input data and weights move.
In this post, I’ll use Python to implement three approaches of 1D output stationary dataflow - one from the textbook, and other two came up by myself. I simulate PEs using the Process class from the multiprocessing library. Dataflows are managed via Queue, and outputs are stored in Array.
Output Stationary 1 - textbook example
The weights are broadcast while activations(i.e., input feature map) are passed through the PEs sequentially.
Notice that the PEs only retrieve weights when the required activations are passed in. Before that, the weights will be stored in the buffer of the queues.
(For the figure on the right, notice that 0, 1, 2… are just index, not real number)
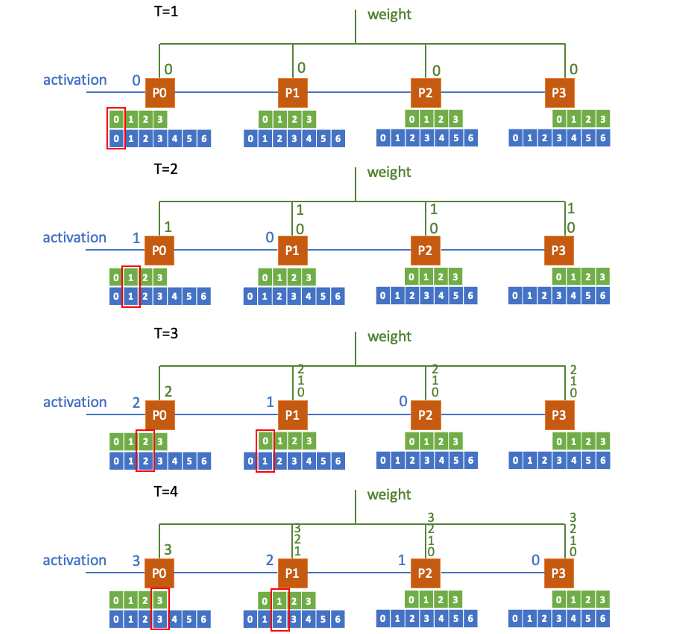
We can observe that in this case each PE needs to store the weight for a long time until the corresponding input is passed in, which in my point of view might not be an efficient way.
Output Stationary 2
In this new approach, we try simply switching the dataflow of the weights and activations. The activations are broadcast while weights are passed through the PEs sequentially.
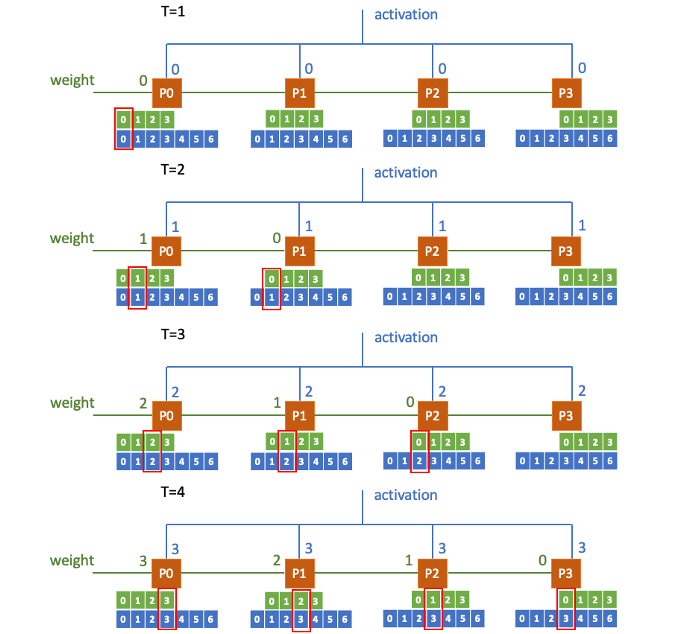
In this case, we no longer need to store any values in PE. The process is more straight-forward, and the runtime is also a bit faster.
Output Stationary 3
In this new approach, the weights are broadcast while activations are passed through the PEs sequentially.
This is a special case where the IDs of the PEs in this approach are arranged in a reversed order. Also, all PEs will not start retrieving the broadcast weight until a certain time_step (when the first activation arrives at the last PE).
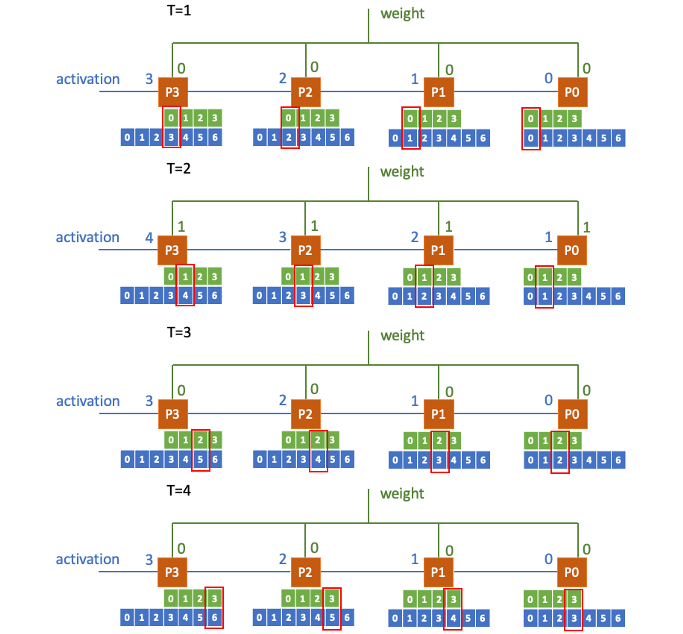
This method also avoids the storing issue, and achieves the highest efficiency among all.
Simulation Result
We tested these approaches using an input feature map of size 64, and the weight of size 4. The floating numbers are randomly generated. We then compared the simulation results with the expected ones.
All three approaches passed the validation, the other two dataflows achieved a slightly faster runtime than the first one. It is also an advantage of the other two that they don’t need extra buffer to store the values.

Enjoy Reading This Article?
Here are some more articles you might like to read next: