Smart TA
an LLM project (USC Directed Research)
Visit our Website: www.coursistant.com
Watch the demo: YouTube Video
Repositories:
Embedding model: GitHub Link
Language model: GitHub Link
Piazza API: GutHib Link
This is an ongoing research project supervised by Professor Young Cho at USC Information Sciences Institute. Our group of four is currently developing a smart TA application that can reply to students’ answers immediately based on a model trained by previous posts. The model is based on RAG(Retrieval-Augmented Generation) architecture, with custom document embeddings.
Custom Embedding
Since the context of our post database are highly domain specific - it mainly concerns with course materials and concepts, a customized embedding model might be more flexible and efficient compared to existing large embedding model like BERT and LlamaIndex.
The processing includes the following crucial procedure: Preprocessing, Vectorizing, Kmeans Clustering, and Histogram Construction.
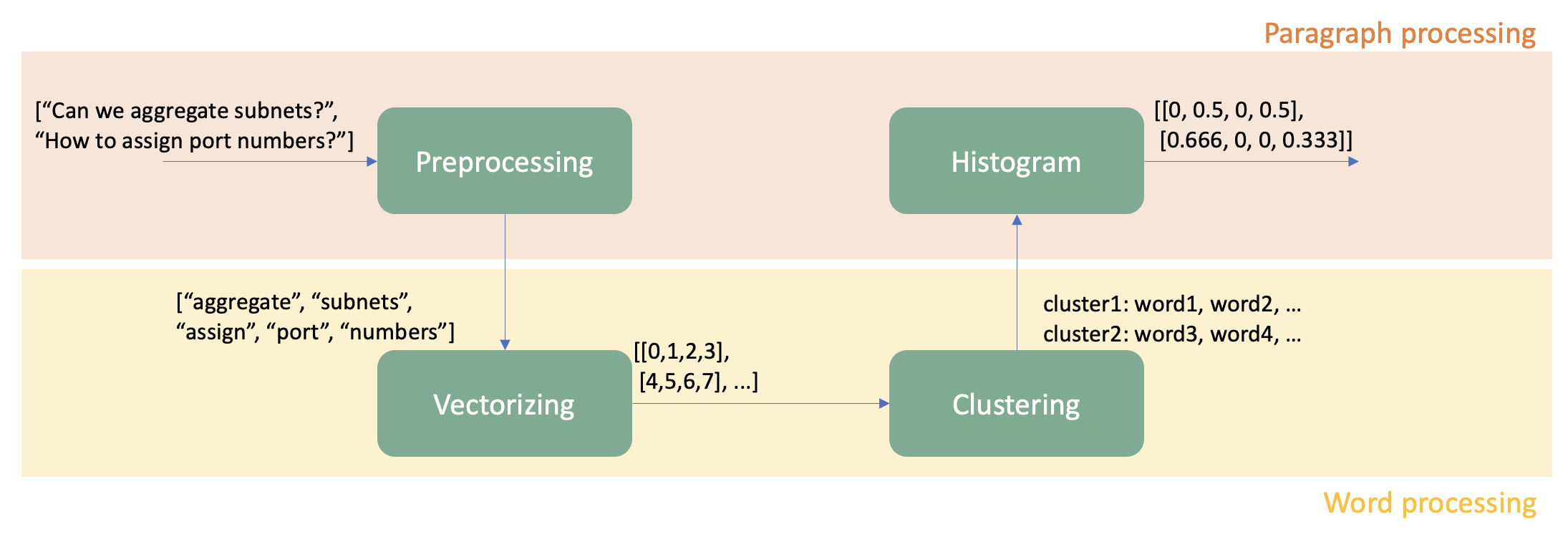
- Preprocessing
- Tool: nltk, sklearn, spacy
- For paragraphs in the raw data, chunk them into small pieces of sentences, and further tokenize them into arrays of words.
- Remove the stop words using static library and TF-IDF (Term Frequency-Inverse Document Frequency)
- Vectorizing
- Tool: gensim.models Word2Vec
- Transform words into vectors based on their surrounding context.
- Kmeans Clustering
- Tool: sklearn.cluster KMeans
- Group words together into k clusters based on the distance of their vector.
- Histogram Construction
- Each sentence is rebuilt into an array of k, with the value in index i representing the frequency of words from cluster i.
- The array is normalized so that all the values add up to 1.
Now, we are able to find sentences with the closest meanings based on their similarities of the histograms.
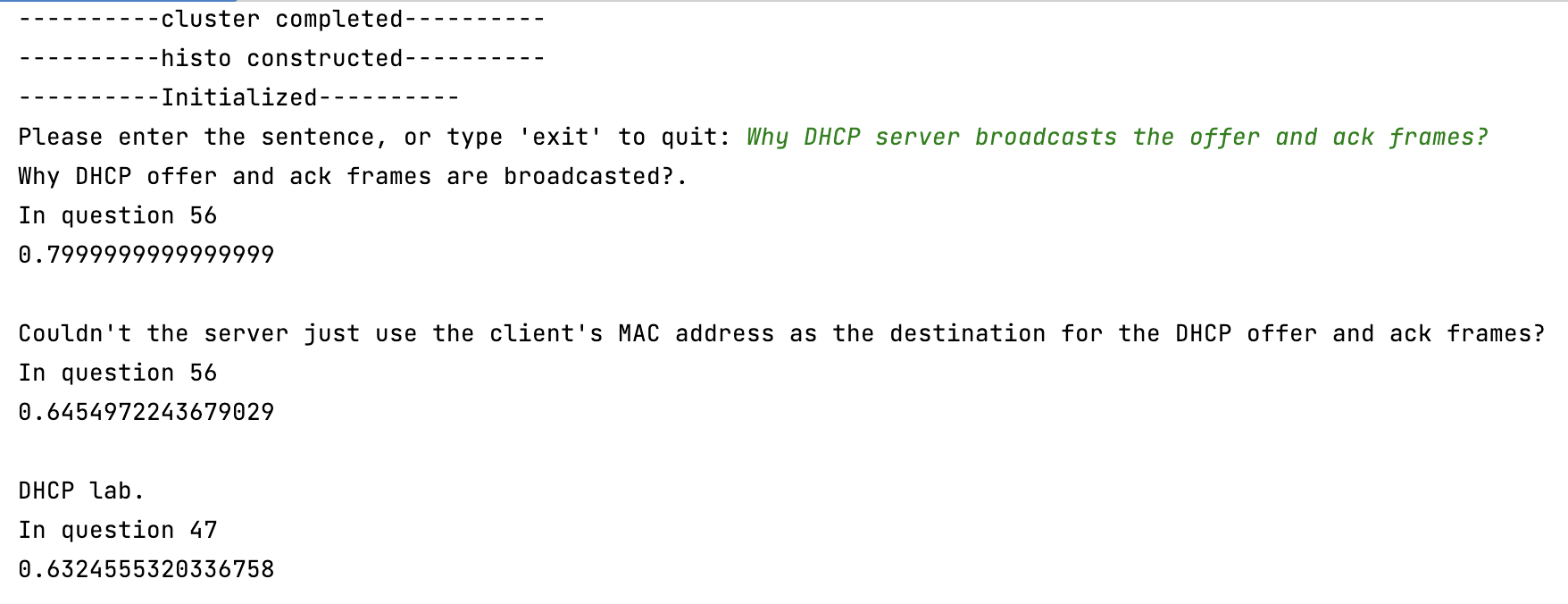
Currently, we’re still tuning the model (optimize stop words removal, cluster size, addition context…) in order to reach a higher accuracy.
Language Model
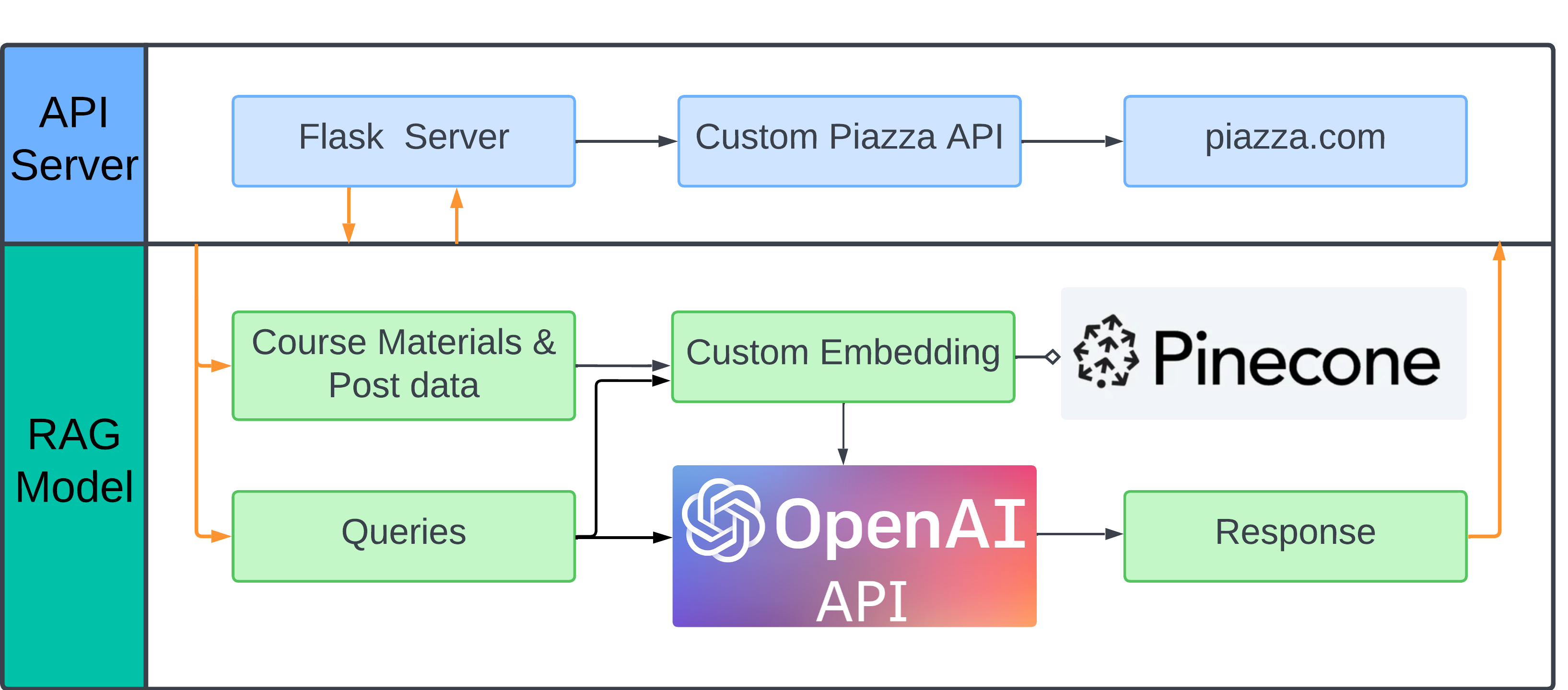
With our custom embedding model connected to Pinecone as vector database and OpenAI API as LLM model, we build the completed model for generating answers for the new questions. In the first step, TAs will feed course materials and archived posts to the embedding model, which will then store all the information into our vector DB. Then, when the new query comes, it will be passed into our embedding model and do a similarity search to retrieve all relevant information. Finally, we feed both the information and the query, along with a prompt, to OpenAI API to let it deal with expression issues such as grammar, and summarize the answer.
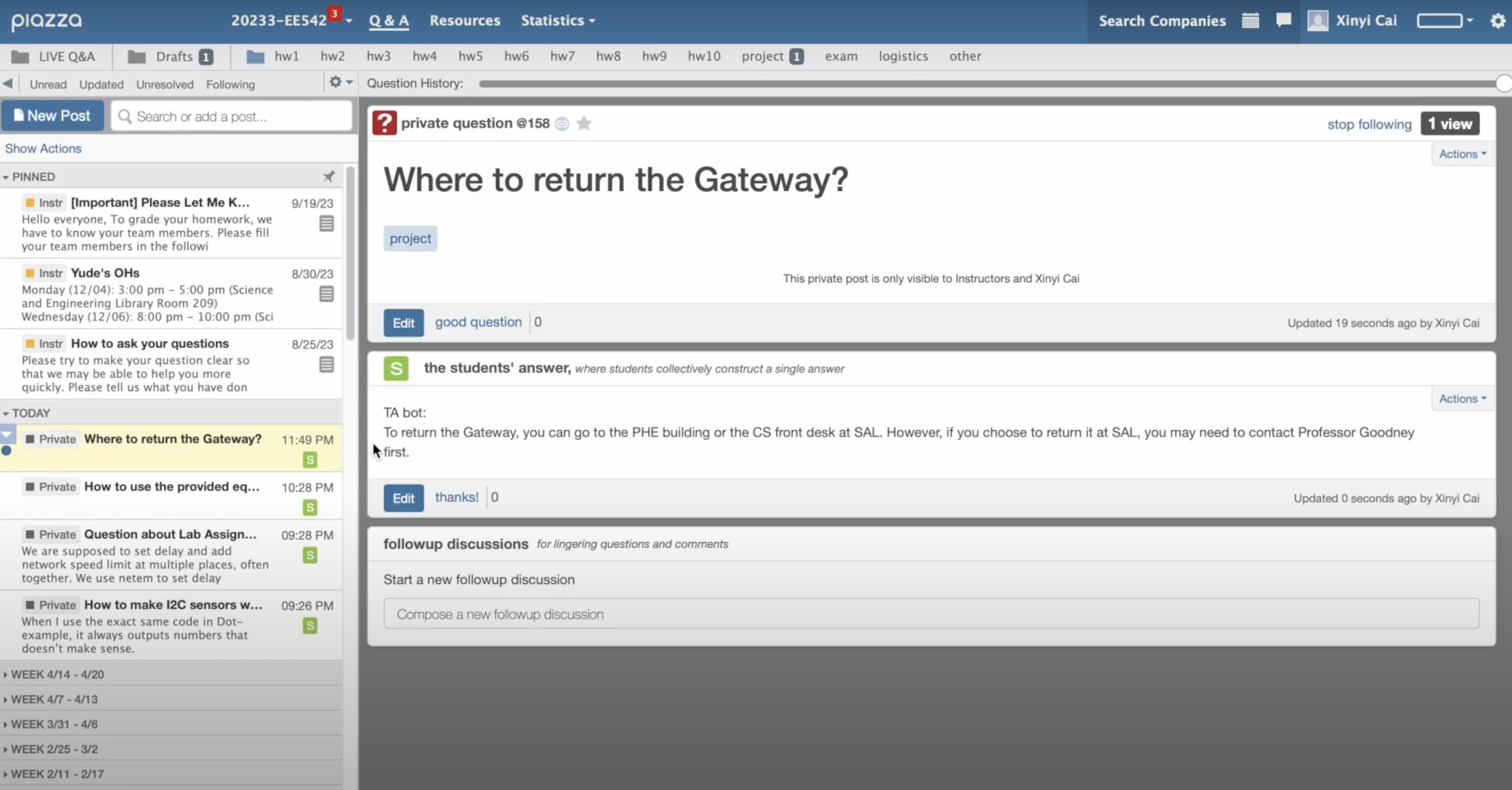
Piazza API
This custom API is built upon this unofficial Piazza client. The principal modifications are: adding functions to get unread posts, supporting student_rule reply, changing authentication mechanism to support multiple session.
These functions are then wrapped into endpoints on the Flask server:
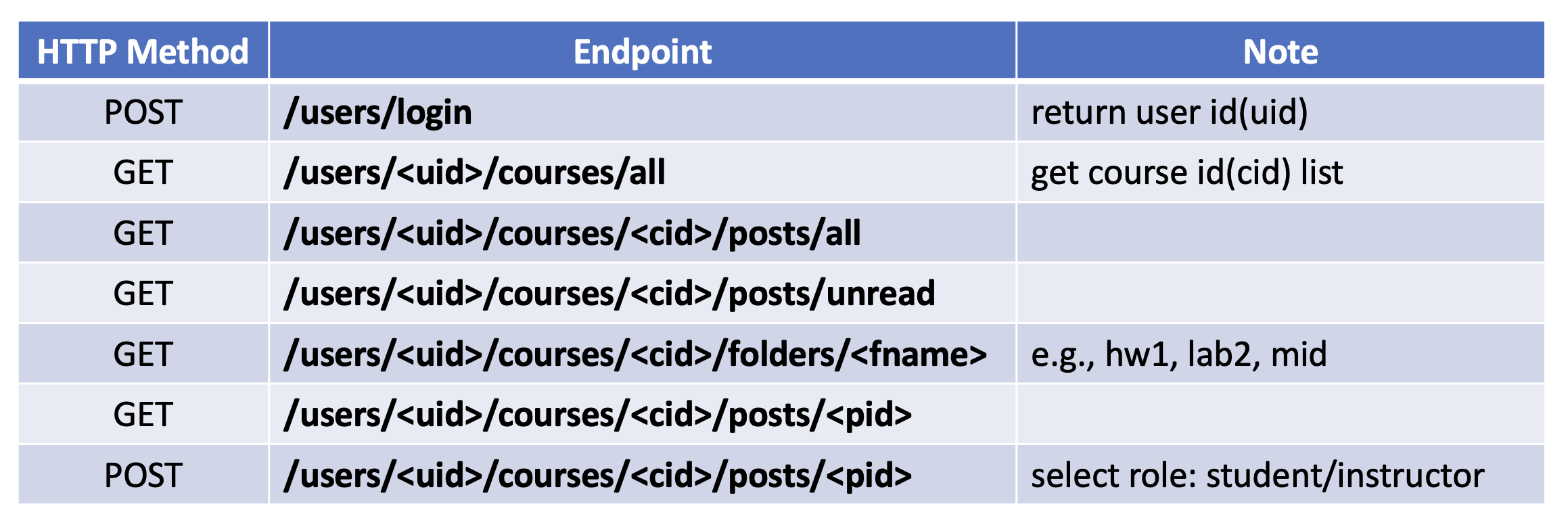
With this server combined with our language model, we can achieve the functionality of immediate automatic reply. Promising to replace TAs in the future!!
My part in this project: Piazza API(completed), Custom Embedding Model & Language Model(Ongoing)